
開發物件導向SOLID 原則
SOLID 是由 Robert C. Martin(Uncle Bob)提出的五大物件導向設計原則,能夠幫助開發人員寫出更加模組化、可擴展、可維護的程式碼。這些原則有助於降低耦合度、提高重用性,並減少系統的技術債。
單一職責原則(SRP, Single Responsibility Principle):每個 Class、Function 或 Method 應該只有 一個明確的職責,確保變更時影響最小,提升可維護性。
開放封閉原則(OCP, Open/Closed Principle):軟體設計應對擴展開放,對修改封閉,可以透過 繼承(extend)或組合(composition) 來新增功能,而不修改原始代碼。
里氏替換原則(LSP, Liskov Substitution Principle):子類別應該能替換父類別,而不影響系統的正確性,可透過 Interface 或 Abstract Class 確保子類別不違反父類別的行為契約。
介面隔離原則(ISP, Interface Segregation Principle):應該將大型介面拆分為更小的專用介面,讓類別 只依賴它實際需要的功能,避免不必要的依賴。
依賴反轉原則(DIP, Dependency Inversion Principle):高層模組不應該依賴低層模組,兩者都應該依賴抽象(如 Interface 或 Abstract Class),以提升系統的靈活性與可維護性。
1. 單一職責原則(SRP - Single Responsibility Principle)
嗯.. 這真的是一個是一個害死人的名稱,很多人會以為他意味每個模組都應該只做一件事。但真正的定義卻並非如此:
按照慣例,先上定義:“A class should have only one reason to change.”
翻譯成中文是:「一個模組應有且只有一個理由會使其改變。」
但是在 Clear Architecture 一書中,作者說到軟體系統改變是為了滿足使用者與利益相關者,所以我們應該把這理由套用到定義上,即變成:
「一個模組應只對唯一一個使用者或利益相關者負責。」
可是如果現在有多個使用者或利益相關者希望以相同的方式改變的話,我們不就會輕易地違反定義了嗎?
所以我們需要為一群希望以相同的方式改變的使用者或利益相關者一個定義,在這邊作者稱之為角色。
最終定義為:「一個模組應只對唯一的一個角色負責。」
對,疑問來了,角色是什麼?這樣做的好處是什麼?違反這原則會帶來什麼壞處?
為什麼原來的定義跟推導後得出的定義會差這麼多????????
所以,要了解單一職責原則我們需要一些例子、一點更具體的想法。
讓我們來看看第一個例子:
假如今天我們在做一個電商平台,而裡面分別有計算消費稅、信用卡手續費的 function,且同時應用在賣家後台與電商管理後台。
class feeCalculator {
public function calcTax();
public function calcCreditCardFee();
}
如果今天信用卡公司跟電商平台有了個協議,
信用卡公司:「每筆單我給貴公司減少 5% 的抽成!」
電商公司高興地想:「那我就可以維持對消費者來 10% 的抽成,自己賺那5%,爽翻天囉!」
然後馬上請工程帥去改程式。
故事的結果當然是工程帥去改同時面對賣家後台與電商後台的 calcCreditCardFee(),然後公司就是少賺了幾千萬,最後工程帥被炒了。Happy Ending!
這邊就可以回到「一個模組應只對唯一的一個角色負責。」的定義,今天因為工程師不知道原來這模組同時對兩個角色負責了 — — 賣家後台與電商管理後台,把不同角色所依賴的程式碼放在一起,他的改動同時造成兩個角色的行為改變,最後導致錯誤發生。
而 SRP 就是希望我們極力避免這種事情的發生,正是要限制改變帶來的影響力。
那上面的錯誤我們又該如何做一個更好的處理呢?
最簡單的想法就是為 calcCreditCardFee() 分別封裝起來,以應對不同的角色
class SalesFeeCalculator { // for 賣家
public function calcTax();
public function calcCreditCardFee();
}class AdminFeeCalculator { // for 後台
public function calcTax();
public function calcCreditCardFee();
}
OK,這樣我們 10 個角色用到很類似的計算 function,我們就要 10 個 class,然後 class 裡面的 function 都只有點一差異,這樣好像又有點怪怪的?
那如果是透過控制項來管理呢?
class FeeCalculator {private role = null;
public __construct(Role role) {
this.role = role
}
public function calcTax();public function calcCreditCardFee() {
if (this.role == Sales) {
return ....;
}else if (this.role == Admin){
return ....;
}else{
return ....;
}
}
}
這樣的類別雖然可以保持簡潔,我們又要面對在一個類別中會同時面向兩個角色的問題。
往更小的分類方向去看,我們會發現一直會改變的是 calcCreditCardFee() 這個方法。如果我們把 calcCreditCardFee() 抽出來獨立使用呢?
interface FeeCalculator {
public function calc();
}class CreditCardFeeHandler implements FeeCalculator {
public function calc(percentage) {
return ....;
}
}class TaxFeeHandler implements FeeCalculator {
public function calc(percentage) {
return ....;
}
}
我們把 calcCreditCardFee() 變為 CreditCardFeeHandler 類別,再在裡面創建一個 calc() 方法。這樣我們不管是那位使用者要使用計算信用卡手續費,只要透過 CreditCardFeeHandler 就可以實例化它的計算方法出來。
另外,可以看到我們使用了 interface 並分別實作到 CreditCardFeeHandler 與 TaxFeeHandler 上。這樣我們的計算類別都可以有效解耦,而且在要注入的情況時,又可以獲得多型的好處。
(不了解 interface?看看物件導向中的介面與抽象類別是什麼 ?)
最後一個疑問,這樣整個結構不就變成一個 function 一個 class 嗎?
是有這樣的可能的!但是我們要了解到,你要實作一個良好運作的模組,除了對外的 function 時,我們其實還有很多資料與方法是私有的。只要這些內容都指向同一個使用者,很多 class 的 SRP 是可以被接受的。
總結一下,角色就是一群會使用該模組的使用者,可能是真的人,也可能是別的模組。所以我們在考慮模組對應的角色時,可以從模組會被誰使用出發。
而這樣做的好處就是可以「分開不同角色所依賴的程式碼」,從而減少不同模組因過度耦合而在改變時所造成的錯誤,同時亦可以更容易的進行測試。
2. 開放封閉原則(OCP - Open/Closed Principle)
相比第一篇 SRP 原則來說,開放封閉原則可以說是好懂三百倍了。
定義:一個軟體製品應該對於擴展是開放的,但對於修改是封閉的。
這樣的中文定義老實我個人認為邏輯不夠嚴謹。這樣的定義是指「一個軟體應該對於擴展是開放的或一個軟體應該對修改是封閉的。」還是「一個軟體製品在面對擴展時是開放的,且擴充時不應修改到原有的程式。」呢?
維基百科的定義是:
系統一旦完成,一個類的實現只應該因錯誤而修改,新的或者改變的特性應該通過新建不同的類實現。但在 Uncle Bob 的文章中,他定義為:
You should be able to extend the behavior of a system without having to modify that system.
我們清楚理解到這是一個「且」的關係,即:
一個軟體製品在面對擴展時是開放的,且擴充時不應修改到原有的程式。
對,就是這麼簡單!
當年他們會提出這樣的原則是有理由的,比如說 Linux Kernel,他們盡量不希望在為一個穩定的 Linux Kernel 版本新增功能時,因為會改動到原有的程式碼而使 Kernel 也要做出大量的修改了,然後出現很多新的 Bug。而是希望在新增功能時,原有穩定的版本還是保持一致,否則 debug 起來就是地獄。
我們可以看到最美妙地遵守 OCP 的幾個常用程式,如 Google Chrome、VSCode等等。我們可以輕易為他們新增很多的 plugin,且不會對原來的主體造成影響。
那怎樣才能達成 OCP?簡單來說,透過 SRP 我們可以就不同因素而改變的模組分類好,再透過 DIP (依賴反向,之後的文章我們會更詳細的說到)來為系統創建一個單向的流程。
具體來說, 我們在說架構時都會把程式分成很多層。而在系統中的最高層,通常都是業務邏輯層,其他層次都是圍繞著業務邏輯層而進行分工。而這種分工比較像以下的架構圖:
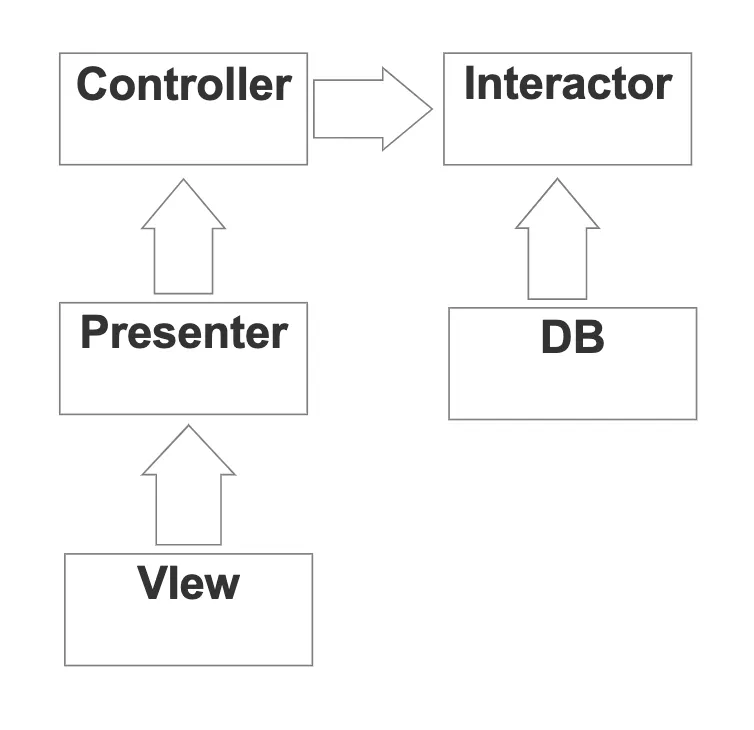
在上圖中,整個架構的核心是 Interactor (業務邏輯層),他會被 Controller 與 DB 所依賴。而 Presenter 又會依賴於 Controller 。
這層層的單向依賴有效於解耦。
在軟體設計中,元件不應依賴於不會直接使用到的東西,如 Interactor 不會直接使用到 View, Interactor 跟 View 之間當然不應有著依賴的關係。同理地,作為底層的元件只需做好自己的「本份」,如 View 就應該是只處理視圖的邏輯,不應也不需要知道 Presenter 是在處理什麼邏輯,這樣的單向依賴可以讓高層元件免受非有依賴關係的低層元件改變影響。
所以在設計架構時,我們要根據如何、為什麼及何時發生變更來分離功能,然後將分離的功能組織到元件階層中。
說了這麼多,OCP 不是要告訴我們程式該怎麼分層、工作該怎麼寫好,而是給出一個解耦的概念,我們應該要朝著就算加了三四五六七個新的功能,我們還是不會影響到原有的程式,更能優雅地設計著!
優雅地設計一個「即使需要功能擴充,亦不需要修改原程式碼的系統」。而這樣的目標就有賴於我們怎麼樣設計我們的程式架構了!
3. 里氏替換原則(LSP - Liskov Substitution Principle)
很多人以為里氏替換原則只是指導我們如何定義子類別。
LSP 的出處是 Barbara Liskov 的一篇論文:Behavioral Subtyping Using Invariants and Constraints
定義:若對型態 S 的每一個物件 o1,都存在一個型態為 T 的物件 o2,使得在所有針對 T 編寫的程式 P 中,用 o1 替換 o2後,程式 P 的行為功能不變,則 S 是 T 的子型態。
嗯。。。希望你們看得懂,反正我 ╮(╯∀╰)╭。雖然定義看起來很複雜,但這樣的定義我認為可以很準確地表達出 LSP 的思想,即:
子型態必須遵從父型態的行為進行設計。
簡單說,假設我們在寫一個模組 P,而模組 P 裡面有用到 Car 類別的物件 car,而今天我們用 BMW 類別的物件 bmw 來替代 car,而 P 的功能都不會被影響的話,那 BMW 就是 Car 的子類別。
也就是說,只要 S 跟 T 替換後,整個 P 的行為沒有差別,那 S 就是 T 的子型態。從類別上來說, S 完全可以繼承 T,成為T的子類別。
那如果我們在子類 Override 父類呢,這樣的動作還符合 LSP 的原則嗎?
我們可以換個角度來看 LSP 原則。
按照 Design by Contract 設計方法,遵守 LSP 就是遵守以下三個條件:
1.子型態的先決條件 (Preconditions) 不應被加強。
先決條件是指執行一段程式前必須成立的條件。使用者在使用子型態前,要確保子型態的先決條件不會比父型態的更強,但可以削弱。
如一個整數相加功能,輸入的參數必須為 2 個整體並回傳一個整數,且輸入的數字不能小於 0 及大於 50 (先決條件)。
let sum = 0;// a,b 必須 >= 0 && <= 50
function add(int a, int b)
{
result = a + b;
return result;
}sum = add(1,5)
子型態在覆寫這功能時,先決條件不能比父型態強。若父型態輸入的數字要求是「不能小於 0 及大於 50」,子型態輸入的數字則不能是「不能小於 0 及大於 51」,但可以是「不能小於 0 及大於 30」。
2.子型態的後置條件 (Postconditions) 不應被削弱。
後置條件是指執行一段程式後必須成立的條件。使用者在使用子型態後,要確保子型態的後置條件不會比父型態的更弱,但可以加強其後置條件。
let sum = 0;// a,b 必須 >= 0 && <= 50
function add(int a, int b)
{
result = a + b; // 回傳型態必須為 int
return result;
}// result 必須等於 sum
sum = add(1,5)//加強條件
let sum2 = 0;
sum2 = add(1,5)
以相同的例子,這邊的後置條件是回傳的型別必須為 int。即子型態不能回傳非 int 型別,如最後把 int 轉成 String 再回傳。
子型態加強其後置條件,如上例,除了 result 必須等於 sum 外,子型態也可以加強條件,讓 result 也必須等於 sum2。
3. 父型態的不變條件 (Invariants) 必須被子型態所保留。
不變條件指不管在何時何地都不能改變,這是構成整個型態的重要條件。同樣地,子型態必須遵守父型態的不變條件,若然加以修改或不遵守,則會導致多型的重大失敗。
所以,只要 Override 有遵守以上三個原則,他就是符合了 LSP 原則。
試想像一下,如果父類與子類在面對一樣的參數時,子類拋出錯誤,而父類並沒有,或者一個子類有不可預期的副作用等等,這些都是名不符實,沒有真的遵從父類的行為。
以單元測試為例,如果今天寫一個多型的測試,但子類的注入得不到跟父類注入時一樣的結果,單元測試就不會通過,也就表示這樣的子類別不符合 LSP 原則。
其實 LSP 在類別的應用上非常容易明白,但真正難以理解的是要將 LSP 放到軟體架構層來看。
在軟體架構層中,我們會期待被同一群使用者所呼叫的介面都有著一樣的行為。
LSP 是指 T只要能被 S 替代,S 就是 T 的子型態。換句話說,我們不希望在為軟體進行某程度的更新後,行為就變得不一致了。如在專案上,現在有套件 A 更新了, 我們會期待套件的更新不會影響原有程式的運作,而不是更新後一堆東西不能用了。
即使用者只依賴於介面,不需要了解到程式的內部在發生什麼事。今天不管是修 bug、是重構、是用全近的語言來寫,讓版本從 1.0 -> 1.1,我們都是期待一致的行為。如此,就是乎合 LSP 原則的軟體架構。
總結一下,繼承請不要隨意使用。因為繼承是依賴性超強的一個特性,如果稍有一項沒有做對,你的子類就會做出超乎預期的行為,在整個系統已經建構起來後,修改起來會是一程地獄之旅。
4. 介面隔離原則(ISP - Interface Segregation Principle)
如果還不知道什麼是介面的話,可以先看物件導向中的介面與抽象類別是什麼 ?
定義:No client should be forced to depend on methods it does not use.
白話翻譯:模組與模組之間的依賴,不應有用不到的功能可以被對方呼叫。
介面隔離原則其實並不困難。就如定義所說,因為模組之間的依賴不應有用不到的功能,所以我們可以透過介面來進行分割,把模組分得更合符本身的角色,也讓使用介面的角色只能分別接觸到應有的功能。
我先舉一個簡單的例子來說明何為違反 ISP:
class Car {
public function void openEngineMode() { /*...*/ }
public function void repairWheel() { /*...*/ } public function void startEngine() { /*...*/ }
public function void move() { /*...*/ }}class Driver {
Car myCar = new Car();
myCar.startEngine();
myCar.move();
myCar.openEngineMode(); // 為什麼我什麼都不會就可以開啟工程模式呢?
}class Mechanic {
Car clientCar = new Car();
clientCar.repairWheel();
clientCar.openEngineMode();
}
上例中,我們看到一個普通人就可以使用 Car 類別中的 openEngineMode() 功能,但這功能其實只是給工程師用的,普通人用很容易會把汽車用壞。這就是一個沒有把功能隔離好的例子。
Car 的部分功能給了不該用到這些功能的角色使用。
這時我們可以用 interface 來做優化,如下:
interface DailyUsage {
public function void startEngine();
public function void move();
}interface RepairUsage {
public function void openEngineMode();
public function void repairWheel();
}class Car implement DailyUsage, RepairUsage {
public function void openEngineMode() { /*...*/ }
public function void repairWheel() { /*...*/ } public function void startEngine() { /*...*/ }
public function void move() { /*...*/ }}class Driver {
DailyUsage myCar = new Car();
myCar.startEngine();
myCar.move();
}class Mechanic {
RepairUsage clientCar = new Car();
clientCar.repairWheel();
clientCar.openEngineMode();
}
透過 interface 來為我們的 Car 類別的不同功能分類,然後不同的角色再分別引用不同的功能。Mechanic 的程式將依賴於 RepairUsage 和 openEngineMode() ,但不再依賴於 Car。那 Mechanic 也不用關心 DailyUsage 和 Driver 的修改。
那架構層面來看呢?
好比當程式是依賴於 Framework 而 Framework 又賴依於 Database 時,當 Database 更換,如從 MySQL 換到 MongoDB,程式將會直接無法使用。
所以多使用介面來進行解藕、把實作隱藏起來、保持抽象,有助我們程式的彈性。
5. 依賴反轉原則(DIP - Dependency Inversion Principle)
定義:高層模組不應依賴低層模組,它們都應依賴於抽象介面。抽象介面不應該依賴於具體實作,具體實作應依賴抽象介面。
什麼是高層模組,什麼是低層模組?
低層模組:該模組的實現都是不可分割的原子邏輯層,如 MVC 中的 Model 層。
高層模組:該模組的業務邏輯多是由低層模組組合而成,如 MVC 中的 Controller 層與 Client 端。
「正常的」程式,可能會有很多高層模組依賴於底層模組。我們常常看到的可能是像以下:
class Controller {
Mysql mysqlDB = new Mysql();
string dbHost = mysqlDB.host;
}我們都在某個 function 或是 某個 class 底下直接使用其他的 class。這樣的問題是變得非常高耦合,如果今天我們要把 Mysql 改成 monogoDB,那整段程式碼應該就是直接換掉重寫了,完全違反了 OCP!
那如果寫成以下的方式:
class Controller {
private Mysql mysqlDB;
public Controller(Mysql mysqlDB)
{
this.mysqlDB = mysqlDB;
} string dbHost = this.mysqlDB.host;}這樣寫是可以算是進了一步,我們使用了依賴注入來把 Mysql 放到 Controller 中,而不是直接在 Controller 中 new 出一個新的 object 出來,可以算是解耦了一點點。
那到底怎麼樣寫才是乎合 DIP 原則的寫法?多用抽象層!
class Controller {
private Database database;
public Controller(Database database) //只注入 Database 介面
{
this.database = database;
} string dbHost = this.database.gethost();
}
interface Database {
public string getHost();
public string getPort();
public string getUsername();
public string getPassword();
}
class Mysql implement Database {
public string getHost() {
...
return host;
}
...
}以上的例子,我們可以看到在 Controller 當中只依賴於抽象層 (interface Database),而 Mysql 類別也同樣賴於相同的抽象層。今天就算是要換成 MonogoDB,那只要一樣用 MonogoDB 類別賴於 Database 介面,Controller不用做出改變就可以加以擴充。
這樣的做法其實是一種將低層模組的控制權從原來的高層模組中抽離,將兩者的耦合只放在抽象層上。
物件的建立則應以抽象工廠模式進行,同樣的原因,就是避免高度耦合的發生。我們來看看以下例子:
class Application {
...
DatabaseFactory db = new DatabaseFactoryImpl();
Database database = db.makeDb();
}interface DatabaseFactory {
public Database makeDb();
}class DatabaseFactoryImpl implment DatabaseFactory {
public Database makeDb() {
return new Mysql();
}
}interface Database {
public string getHost();
public string getPort();
public string getUsername();
public string getPassword();
}class Mysql implement Database {
public string getHost() {
...
return host;
}
...
}
以上的工廠能讓高層模組最低限度地依賴其他的模組 (只依賴於 DatabaseFactory 介面),而實現邏輯的會是於 DatabaseFactoryImpl 中發生。
同時,DatabaseFactory 產生的物件又能被 Database 介面所使用,讓 Application 這個類別完全不必接觸到非抽象層,將耦合性大大降低。
有些朋友會想到那在更大的範圍來看軟體時,那程式不是一樣依賴於 Framework 跟 Database 嗎?
對的,沒錯,程式的確是依賴於這樣不夠抽象的層次,但是
我們知道可以信任他們不會改變,所以我們可以容忍那些具體的依賴關係。
不是所有時候都需要 100% 按照 SOLID 原則來設計,這樣只會變得沒完沒了,總會得到一個無法再相依賴於抽象層的模組。
不要過度設計。